Amazon S3
Amazon S3 ist meines Erachtens die günstigste Möglichkeit, Dateien auf einem externen Webspeicher unterzubringen. Die Kosten betragen momentan (für Europa):
- Storage: US-$ 0,18 per GByte/Monat
- Daten-Transfer (Download): ab US-$ 0,18 per GByte/Monat (wer mehr als 10 Terrabyte/Monat runterladen läßt, bekommt es günstiger - aber das ist wohl in der Regel für uns Amateure nicht der Fall ). Für das Hochladen berechnet uns Amazon US-$ 0,10 per GByte.
- Requests kosten noch einmal extra (Amazons S3 funktioniert ja bekanntlich via REST): US-$ 0,012 je 1.000 PUT- oder LIST-Requests und den gleichen Preis je 10.000 GET- oder alle anderen Requests (wobei DELETE für umme zu haben ist).
Die meisten meiner statischen Seiten wie auch dieses Wiki werden mittlerweile bei Amazon S3 gehostet.
Import/Export
Anwender, die große Datenmengen auf S3 kopieren wollen, können auch Festplatten einschicken. Der Dienst AWS Import/Export spart beim Transport großer Datenmengen Zeit.
Die Kosten sind relativ niedrig - Amazon verlangt pro Festplatte pauschal 80 US-Dollar. Dazu kommen 2,49 US-Dollar pro angefangene Stunde, die der Datentransfer im Rechenzentrum dauert. Die Portokosten sind im Preis nicht enthalten. Amazon schickt die Platte zurück. Auch der umgekehrte Weg ist möglich: Amazon kopiert S3-Daten auf Kundenfestplatten und schickt die Datenträger zu.
Mini-Tutorial
Nun haben viele Angst vor dem REST-Interface, aber es gibt glücklicherweise Tools, die den Up- und Donwload ebenso komfortabel erledigen, wie es der User von herkömmlichen (S)FTP-Clients gewohnt ist.
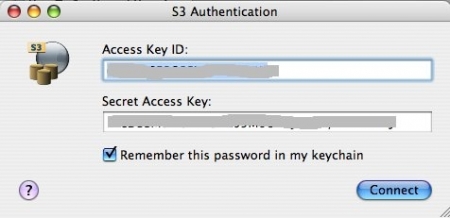
Doch zuerst müssen wir uns einen Account bei Amazon besorgen. Das geschieht über diese Website von Amazon. Zurück erhalten wir eine Access Key ID und einen Secret Access Key. Man kann sich das so vorstellen wie einen Benutzernamen und ein Kennwort, nur das beides ziemliche Zeichenmonster sind.
Nun benötigen wir einen Client. Ein möglicher Client ist der S3 Browser (BSD-Lizenz), der eine sehr leicht zu bedienende Benutzeroberfläche für Amazons Webservice bietet. Wen wir Ihn aufrufen, fordert er uns zuerst auf, uns mit unserem Access Key ID und unserem Secret Access Key bei Amazon zu identifizieren:
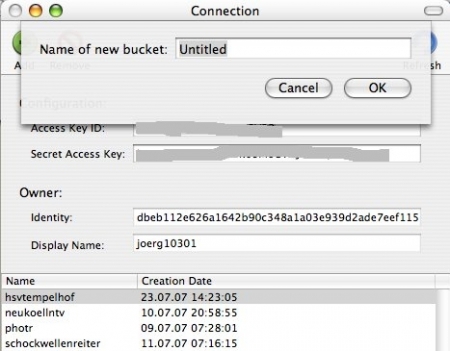
Als nächstes müssen wir (mindestens) ein Bucket anlegen. Buckets sind so etwas wie Ordner, nur daß sie Amazon-weit eindeutig sein müssen, daher sind populäre Namen vermutlich schon vergeben. Das Anlegen von Unterordnern (Sub-Buckets) ist leider nicht möglich. Wenn Ihr auf den grünen Plus(+)-Knopf klickt, könnt Ihr Euren Bucket-Namen eingeben und testen, ob er schon vergeben ist:
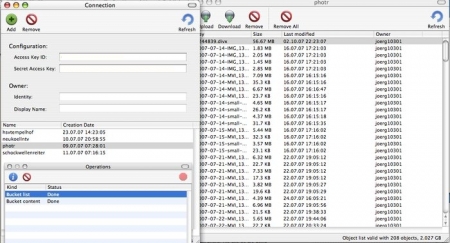
Das Hochladen geschieht jetzt einfach, indem Ihr Eure Datei (Eure Dateien) auf das offene Fenster schiebt (alternativ könnt Ihr auch die jeweiligen Up- und Download-Knöpfchen obenlinks drücken und die Datei(en) über die Auswahlbox anklicken). Wenn Ihr versucht, mehr als drei Dateien auf einem Rutsch hochzuladen, bekommt Ihr vermutlich ein Timeout. Jedenfalls ist es bei mir immer so, daher lade ich alles immer in Dreierhäppchen hoch.
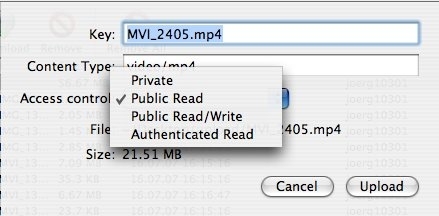
Zum Schluß fragt Euch Das Programm noch, welche Zugriffsrechte die Datei haben soll, im Regelfall ist Public Read das Gewünschte.
Der Rest ist einfach. Die URL für Eure Datei hat immer folgende Form:
http://s3.amazonaws.com/EUER-BUCKET-NAME/EUER-DATEI-NAME
Und Ihr könnt ihn überall da einsetzen, wo Ihr jede andere HTTP-URL ebenfalls einsetzen könnt, also zum Beispiel auch im Flowplayer (GPL, z.B. für Flash-Videos).
Quellen
- Dieses Tutorial wurde von dieser Seite inspiriert: How To Set Up and Host A Publicly-Accessible File on Amazon S3 (Simple Storage Service).
- Und was man noch alles Schönes mit Amazons S3 und dem S3-Browser anstellen kann, findet Ihr hier: Automatically backup your Mac to Amazon S3.
Links
- Amazon S3 Homepage
- AWS Import/Export
- Amazon Web Services Blog: Ship Us That Disk!
- Tutorial: Dateien auf Amazon S3 unter eigener Subdomain hosten
Sie sind hier: Start → Webworking → Webservices → Amazon → amazons3.txt